For the past few months, the development of Dew language has been going on smoothly. The language implementation is now mostly completed except for a few things like high-level optimizations and game-specific features. I am now using Dew everyday to produce some simple and interesting animations here. At this point, the foundation of language implementation now feels pretty solid; and the language design feels also great, so that I can think and program at a very high level when creating the animations.
In the last few weeks I got multi-core parallelism working properly with Dew, which is a really exciting feature. Parallelism in Dew requires minimum effort to use: the programmer just needs to mark some external function calls to be asynchronous, and then the functions will be automatically called from threads in different CPU cores for parallelization. The performance is also great, and benchmarks show it can scale well to a large number of CPU cores.
I have had parallelism in mind ever since very early design stages. A stream-based language lends itself naturally to parallelism, since each stream can be evaluated separately from each other. While parallelizing such languages may seem easy to do in theory, a language implementation has to work with many low-level details exposed by the operating system and the hardware to be efficient. In this blogpost, I am going to talk about implementation strategies involved to make Dew efficient in parallelism.
Concurrency
I use one ‘logical’ thread for each of the Dew streams. The number of streams could be very large. In a benchmark I am able to get 500000 simple streams running sustainedly within the time budget of a typical game. Before I make these logical threads run parallelly, I first consider how to make them run concurrently.
The naive approach to get concurrency is to use preemptive threads provided by the operating system, but it is well-known to have a high overhead, and can’t support the large number of Dew streams. Therefore I have to implement a mechanism to run these logical threads concurrently within a single OS thread, and switch among these logical threads cooperatively.
There’re generally two approaches to implement logical threads: stackful coroutines (also known as fibers) and stackless coroutines. Despite the name, both kinds of coroutines can be used to implement logical threads with stacks. With stackful coroutines, each logical thread is a single coroutine; while with stackless coroutines, each stack frame of a logical thread is a single coroutine.
I chose stackless coroutines for Dew implementation. Stackful coroutine is easier to implement and may have more efficient function calls, but it requires a call stack allocated for each of the coroutines, costing both memory usage and CPU cache utilization, and is unacceptable for the large number of logical threads.
Dew compiler is based on LLVM. To implement stackless coroutines, I happily found that LLVM already has LLVM coroutines for stackless coroutines. However unfortunately, I found LLVM coroutines somewhat bloated and misaligned for my purpose. LLVM coroutines are mostly designed for the upcoming C++ feature of async functions. To use LLVM coroutines, one has to define all relevant LLVM IR functions in a special and convoluted form. Additionally, LLVM coroutine is designed for the general case, and is not necessarily optimized for my specific usage.
So I decided to roll my own implementation of stack coroutines. To implement stack coroutines, the key is a continuation-passing-style (CPS) transform. Instead of implementing the CPS transform directly in Dew compiler, I decided to implement it as a LLVM pass. This has two advantages:
- The Dew compiler itself is much simpler. I can mostly ignore the concurrency implementation for other parts of the compiler, and focus on the core logic of Dew to LLVM IR code generation.
- By implementing CPS transform as a LLVM pass, I can use LLVM to do some middle-end optimizations for me before the CPS transform. This is reported to have benefited the performance of LLVM coroutines.
This is not the only customization that I did to LLVM/clang. A custom LLVM may sound overwhelming work, and but it’s not actually so scary once I got familiar with the LLVM code base. For this particular CPS transform pass I added to LLVM, I was able to reuse the hard work already done for the LLVM coroutines, and the implementation is actually quite simple. The main part of the CPS transform only has 300+ lines of C++ code.
Parallelism
With the logical threads ready to be run concurrently in an OS thread, the typical approach to get parallelism is to use a pool of OS threads, and each thread at one time picks a pending logical thread to run. This approach is known as N:M threading, and is used by many other programming languages.
But I didn’t follow this typical approach. Instead, I make all logical threads to be run in a single OS thread, and introduced the notion of asynchronous external function calls. Only asynchronous external function calls are dispatched to a thread pool and executed in parallel.
For example, consider the following contrived example, func1 is an external function defined in the game engine, and is called twice for each Dew frame.
extern func func1: int32 -> () = "func1"
let x1 = dew -> func1 1
let x2 = dew -> func1 2If we want to parallelize the two func1 calls, we only need to make a very simple change:
let x1 = dew -> (async func1) 1
let x2 = dew -> (async func1) 2In the above code, the async operator means that we want the asynchronous version of external function func1.
The reason why I didn’t follow the typical N:M threading approach is that Dew is intended for game scripting and not a general purpose programming language. When programming with Dew, most costly computations are expected to happen in the game engine, and not directly in Dew programs.
Compared N:M threading, my approach of asynchronous external calls has the following advantages:
- Much fewer cross-thread synchronizations are needed. Although Dew is designed so that all constructed objects is immutable and this helps to reduce synchronization, we still need to synchronize internal mutable information like whether each stream has been evaluated.
- Number of tasks dispatched to the thread pool is much smaller. This is very important for reducing synchronizing cost when there’re many tasks, as indicated by benchmarks. With 500000 streams, I expect 30000 asynchronous external calls to be reasonable, and so 500000 tasks to be dispatched to thread pool is now reduced to 30000.
- Implementation is also easier and simpler. This is easy to see because Dew programs now run in a single thread.
To further reduce number of tasks dispatched to the thread pool, I group asynchronous external calls into batches. When the Dew runtime sees an asynchronous external call, the runtime delays its dispatch for a while, and only dispatch it to the thread pool when it has been delayed for too long or the runtime has collected sufficient number of calls for a batch.
In the thread pool, each thread is pinned to a single logical CPU core. The thread pool uses a single multiple-producer/multiple-consumer (MPMC) queue for distributing tasks. I avoided synchronization primitives provided the operating system, and used atomics to reduce synchronization overhead. My implementation of asynchronous external calls requires a temporary buffer for each call, and to eliminate false sharing, I allocate these buffers linearly from a dedicated asyncheap, which is cacheline-padded between two asynchronous external call batches.
Not only Dew is parallelizable within a single instance, the runtime is carefully written so that different Dew instances can be run on different OS threads for parallelization.
Benchmark
Benchmark is done with a simple Dew program.
let chunks = linit nchunks $ fun _ ->
makework chunksize
let work chunk = dew ->
(async dowork) chunk chunksize
let main = lmap work chunksAfter the initial setup, main will be a list of nchunks streams, each of which does an asynchronous call dowork into to game engine for each Dew frame.
Each makework call returns a newly allocated cacheline-aligned memory block. And dowork is defined on the game engine side in three different ways for testing different workloads.
// for workload of 'none'
int* sc_dowork(int* chunk, int chunksize) {
return chunk;
}
// for workload of 'arith'
int* sc_dowork(int* chunk, int chunksize) {
// it appears that the loop is not optimized away
int x = chunksize;
for (int i = 1; i <= chunksize; i++)
x *= chunksize;
return chunk;
}
// for workload of 'memory'
int* sc_dowork(int* chunk, int chunksize) {
for (int i = 0; i < chunksize; i++)
chunk[i] = chunk[i] * 2;
return chunk;
}The benchmarks are done with a 32-core AMD Threadripper 3970X, with quad-channel RAMs of DDR4-3600C16. The first 31 physical cores are reserved solely for benchmark use. The main Dew thread is placed on the first physical core, and threads in the thread pool are placed starting from the second physical core. The benchmarks differentiate whether hyperthreading is used. If hyperthreading is used, one thread is allocated for each logical core, otherwise one thread is allocated for each physical core.
The first frame of the benchmarked program is ignored, and the average time and the maximum/worst time of the next 10 frames are recorded. In the following graphs, speedup calculated based on average time is reported as round dots, and speedup based on worst time is reported as an extra line.
For the following benchmark results, nchunks is fixed at 30000, the asynchronous calls are dispatched in groups of size 100.
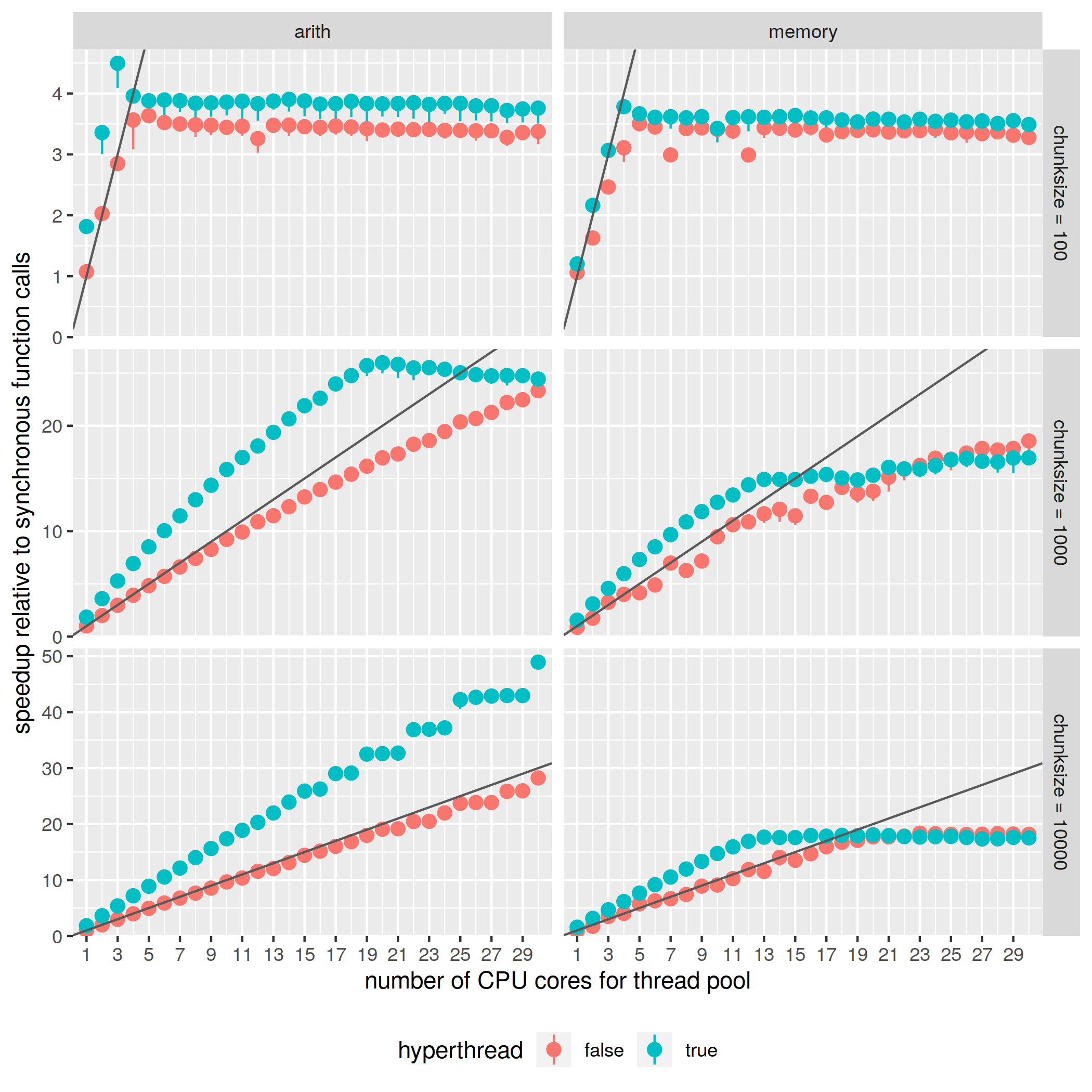
At the first glance, the results doesn’t look good for chunksize=100. But at 4 cores with hyperthreading enabled, each frame already costs as low as 1.80ms, which is very close to the baseline result of 1.62ms, where workload is changed to none and other conditions remain the same. So most of that 1.80ms is spent on the sequential code and synchronization overhead that can’t be parallelized. By Amdahl’s Law, it’s normal to see it doesn’t scale well. However, I don’t consider this to be a performance drawback for Dew, because 30000 asynchronous calls are already quite a lot for one game frame. It’s more likely to see bottleneck elsewhere if more than 30000 asynchronous calls are required.
Another performance degradation is observed with the memory workload when the number of CPU cores used is large. This is probably because of hitting RAM or CPU cache bandwidth limits, and we can do nothing about it here on the level of Dew implementation.
Other than these two issues discussed, the benchmark Dew program scales almost perfectly.
Cache locality
A fundamental weakness of the approach of asynchronous external calls compared to N:M threading is that it breaks cache locality. Each external calls could have some cache locality when executed sequentially, but by making them asynchronous and dispatch them to different OS threads, the original cache locality is lost.
To see the impact of cache locality loss, the work function in the benchmark is modified as follows:
let work chunk = dew ->
for i = 1 to seq do
(async dowork) chunk chunksize
doneWith nchunks = 1000, seq = 30, chunksize = 100, the results of memory workload is as follows:
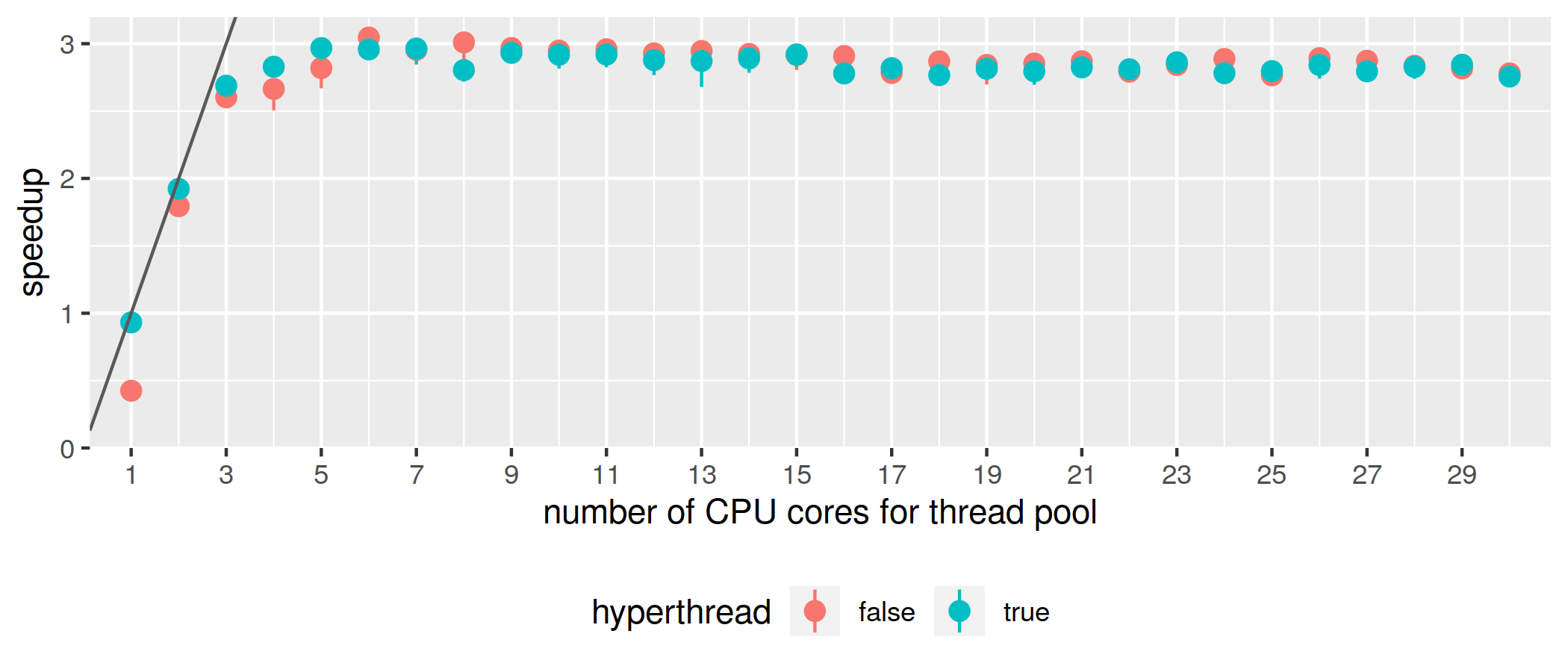
It’s clear that cache locality loss does hurt a lot when there’s a single thread in the thread pool, but as more threads are available, the performance actually scales fine. The maximum speedup being only 3 does not look like an issue, because at speedup = 3 the frame time is already as low as 1.2ms.
Conclusion
Performance has been a very important goal when implementing Dew. Performance by itself is not interesting; but with better performance, I can create more complex game scenes, programmed with higher level constructs.
Due to physical limitations of CPU chips, we will see more and more cores in a single CPU. Parallelism was already a recognized important problem at the time when Dew was initially conceived ~8 years ago, but somehow CPUs with a large number of cores never got quite mainstream until very recently. Now the top-end of consumer CPUs from AMD have 16 cores, and CPU with 8 cores is a pretty standard configuration for a gaming PC.
I previously had a failure when implementing a stream-based framework, so I was expecting difficulty in implementing parallelism for Dew, but the actual implementation turned out to be even more difficult. I learned many low-level things like CPU cachelines and memory fences along the way. With Dew parallelism working, the efforts all seem worthwhile.